





 Alex Vereshchagin
Alex Vereshchagin
Table of Contents
What does “semantic core” actually mean? Many ASO specialists habitually call a simple list of keywords a semantic core. They collect such lists based on query frequency, search suggestions and competitor analysis, then add those words directly to an app’s metadata. The assumption is that the more popular words you mention exactly, the better your app will rank. But is that really the case?
Summary of the article
In this article I show why the familiar “semantic cores” in ASO are often just lists of popular keys and do not reflect the real semantic structure of queries. This approach grew out of lexical search logic, where we look for literal word matches. Practice and changes in search architecture show that this is no longer enough.
Analysis of hundreds of iterations from 2020–2025 shows that text edits increasingly expand the set of indexed queries in positions 21–50 and 51–100 rather than giving stable growth at the top. Even more advanced cores remain “lexical”: they do not show meaning duplicates, do not separate different usage scenarios and do not give an objective picture. Decisions on priorities often remain subjective.
I then explain the industry’s move to meaning‑based search and hybrid models, where a lexical layer selects candidates and semantic and behavioural signals refine ranking. In this context, simply stuffing metadata with synonyms and loosely relevant keys can reduce positions because the description vector is blurred across topics. It is better to keep meaning groups clean and develop them coherently.
Finally, I give a practical method for constructing a truly semantic core in vector space: collect a wide pool of queries, obtain embeddings, build a proximity graph, cluster, prioritise clusters by potential, select formulations for intents and visualise coverage. Such a core becomes not only an ASO tool but also a source of product insights.

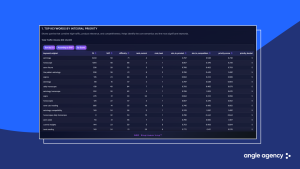
What the analysis of hundreds of iterations in 2020–2025 showed
The traditional ASO approach focused on exact word matching. In essence, a semantic core for us became a set of separate search queries that we distribute by frequency and add to metadata. After 2–4 weeks we analyse the effect of this metadata on positions and do the next iteration. And so on ad infinitum.
Recently I started to build predictive analytics based on machine learning to estimate in advance what increase in visibility and conversion particular text iterations would give. I used hundreds of iteration reports from our own projects, clients and industry colleagues over 2020–2025: what was in metadata, what was changed, what result was obtained, whether motivated traffic, advertising and other factors were used. This is almost a perfect data set for analysis.
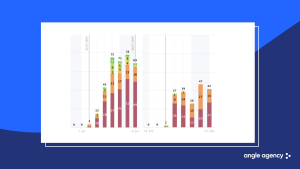
By 2025 it became clear that textual iterations no longer work as well as in 2020 and primarily increase the number of indexed queries in positions 21–50 and 51–100. Shifts in the top buckets (top 1 and top 2–5) by 1–3 positions happen much less often and depend not only on text. The main effect of such iterations is expanding reach rather than rapid growth in installs. Meanwhile 70–90 % of organic traffic usually come from 5–15 keys. Losing even one strong query noticeably drops installs.
Most importantly, all these endless dances with keys do not perform the function expected of them. The problem lies directly in the semantic cores.
What is wrong with semantic cores
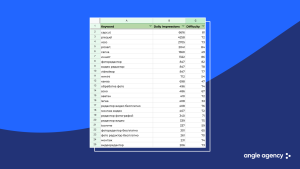
Here is a typical semantic core of 2021: it is essentially a three‑column table listing keys, approximate traffic and conditional promotion difficulty. You cannot judge relevance and priority for each key based only on traffic and difficulty. I do not know how it was used, but this is a real document someone sent me.
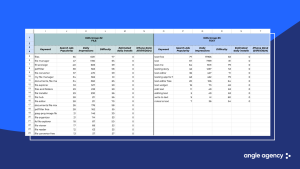
A more recent 2024 core distributes keys by group and adds extra metrics. There is minimal segmentation of queries by topic and the ability to assess not only raw traffic but also potential install capacity of a cluster. But we still do not see which queries actually duplicate each other, which describe different scenarios, which pull branded traffic and which do not. Any decision about “which key to keep, which to drop, which to strengthen in metadata” remains a matter of subjective expertise rather than an analysis of the semantic structure of the query space.
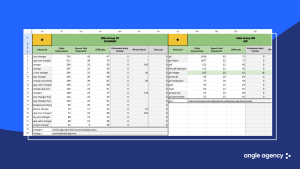
Early 2025 examples show a specialist breaking phrases into tokens and combining them manually to fill all 100 characters of the keywords field. Fundamentally the approach remains the same: all decisions are made at the level of individual words and their combinations. Tokens are selected by frequency and common sense, not based on real semantic proximity in the overall space. We still work with lexicon, not a vector model.
Refreshing how lexical and semantic search work
As comments on my previous article suggested that not everyone understood what I wrote, this time I will lay it out simply with visual examples.
Lexical search
Lexical search is a mechanism where the system looks for exact word matches in metadata. In other words, if a query word is not mentioned, your app will not appear in results. During indexing the algorithm selects candidates only by presence of words. Historically this practice led to collecting a semantic core of popular queries and inserting them into text to cover as many combinations as possible.
Move to search by meaning
Then came 2025, when both Apple and Google openly stated they were moving to search by meaning (natural language search). In September Google Play introduced Guided Search — search by goal or idea rather than just by app name or keywords. Earlier, in May, Apple announced that the App Store had learned to understand everyday language.
This is called semantic search. Instead of looking for exact words, the algorithm transforms the query and app texts into semantic representations (vectors) and compares them. With semantic search the system can show a result even if there is no exact word match, as long as the description is close in meaning to the user’s request.
In practice, modern stores use hybrid models: candidates are first selected lexically (by words), and their ranking is then refined using semantic factors and additional signals. Another scheme runs two searches in parallel—one on keywords, the other on vectors—and then merges and mixes the result lists.
I implemented similar logic to select the most relevant keys. First comes the lexical layer: I remove overt rubbish, fragments and non‑relevant queries. This leaves a candidate set of valid keys worth working with. Then the semantic layer kicks in. For the product and competitor descriptions I compute embeddings, measure proximity, add demand signals—download indices, positions and whether competitors rank. These are combined into a single mask: semantically strong keys pass immediately; keys of medium relevance are kept if there is real demand and visibility data; keys without meaning and without signals are discarded. As a result the final core is the intersection of queries that are close in meaning to the product and queries confirmed by user behaviour.

 Michael Subins
Michael Subins